利用Android源码,轻松实现汉字转拼音功能
今天和大家分享一个从 Android 系统源代码提取出来的汉字转成拼音实现方案,只要一个类,560 多行代码就可以让你轻松实现汉字转成拼音的功能,且无需其他任何第三方依赖。
需求场景
实际开发过程中需要用到实现汉字转成拼音的场景比较常见,如:通讯录里的联系人字母导航栏,为没有设置头像的用户生成一个名字首字母的头像,国家(省份、城市)字母导航栏,搜索关键字转换成拼音等。 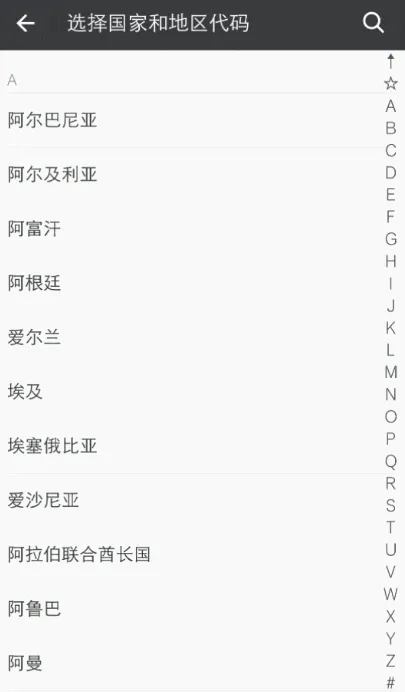
实现方案
Android 平台上将汉字转换成为拼音已经有一些开源的第三方实现方案,如 pinyin4j 和 TinyPinyin
pinyin4j:https://sourceforge.net/projects/pinyin4j
TinyPinyin: https://github.com/promeG/TinyPinyin 以上这两个实现方案,都需要引入不少类以及一些相应的编码文件,这里和大家介绍一个比上面两个方案还要精简的实现方案,只要 560 行代码且无需依赖于其他任何编文件的实现。这个类是从 Android 系统通讯录源码中提取的,类名为 HanziToPinyin,其类文件路径如下:/packages/providers/ContactsProvider/src/com/android/providers /contacts/HanziToPinyin.java
这是一个很独立的类,需要使用的项目直接拷贝到自己对应的工程里面即可使用,需要注意的是,我是在 Android 4.2.2 的系统源码中拷贝出来的,为什么选择 4.2.2,一个是 4.2.2 之后(4.3 开始)的 HanziToPinyin 不再可以独立使用,需要依赖于 Transliterator,而这个类我们是无法直接引用的。而 Android 2.x 的 HanziToPinyin 在测试了很多转换的结果发现是错误的,所以选择了最后一个可以采纳使用的版本 Android 4.2.2。 ##如何使用 HanziToPinyin 这个类的代码量非常少,结构也非常简单
下面简单的说明一下如何使用,非常简单,只需要把需要转换的汉字传入 get 方法即可获取返回的拼音结果
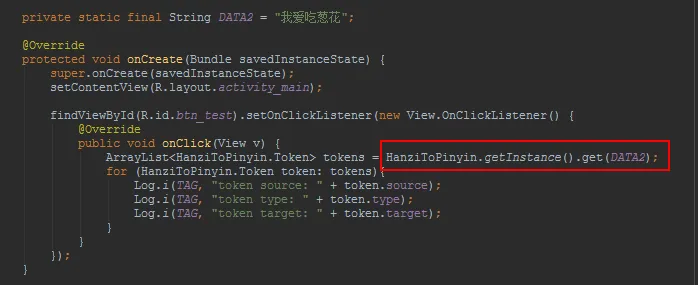
其返回的数据结构是一个 HanziToPinyin.Token 的 ArrayList,HanziToPinyin.Token 是 HanziToPinyin 中的一个公共静态外部类,
其分别有 type、source、target 等三个成员变量,type 是标识 token 的类型,有三种不同的取值 1(拉丁文),2(拼音),3(未知),source 是输入的中文,target 则是中文转换后对应的拼音。这里还有一个细节需要注意一下,只拷贝 HanziToPinyin 在原生系统上使用是没有问题的,但是在国产手机的 ROM 上则无法正常使用,需要加上下面三行代码做适配:
否则 HanziToPinyin 的初始化状态会设置错误,而导致无法实现汉字转换成拼音。
内部实现
了解完如何使用后,我们来简单窥探一下 HanziToPinyin 内部是如何实现的,先来看一下类中比较耀眼的两个数组 UNIHANS 和 PINYINS(两个类很长,截图没截全,大家自己看代码吧) 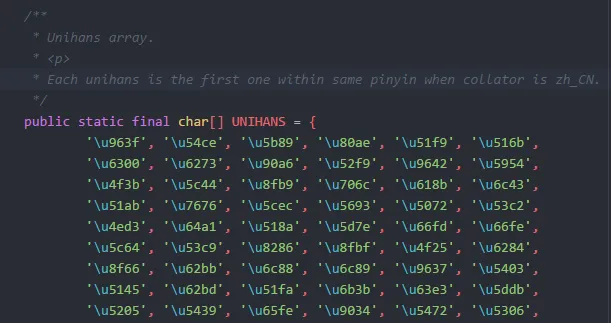
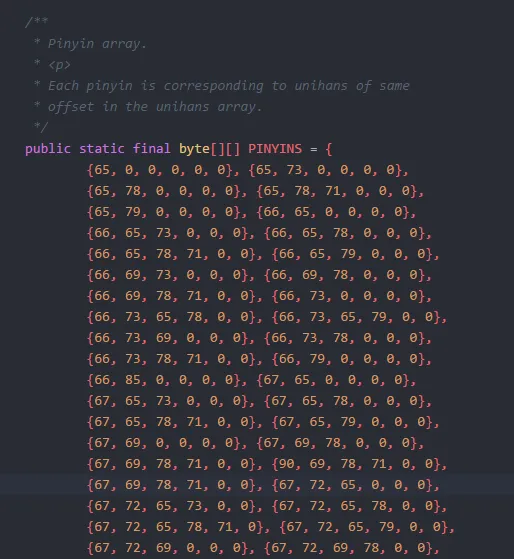 其中 UNIHANS 是一组汉字对应的 unicode 编码,而 PINYINS 则是 UNIHANS 中每个元素对应的拼音的 ASCII 码,如 UNIHANS 的第一个元素是\u963f,其对于的中文是阿,换成拼音则是 A,而 A 对应的 ASCII 码用十进制表示则是 65,对应的就是 PINYINS 的第一个数组中的第一个元素,至于为什么后面有 5 个 0 的元素,主要是因为汉字的拼音最长的有六个字母(例如:chuang),而阿只有一个 a,所以后面的 5 个空位就需要用 0 来填充了。我们在调用 get 方法时将中文以 String 的形式传入,方法内部会遍历 String 中的每个元素,为其生成对应的 Token,也就是我们最后拿到的那个 ArrayList 中的结果。
其中 UNIHANS 是一组汉字对应的 unicode 编码,而 PINYINS 则是 UNIHANS 中每个元素对应的拼音的 ASCII 码,如 UNIHANS 的第一个元素是\u963f,其对于的中文是阿,换成拼音则是 A,而 A 对应的 ASCII 码用十进制表示则是 65,对应的就是 PINYINS 的第一个数组中的第一个元素,至于为什么后面有 5 个 0 的元素,主要是因为汉字的拼音最长的有六个字母(例如:chuang),而阿只有一个 a,所以后面的 5 个空位就需要用 0 来填充了。我们在调用 get 方法时将中文以 String 的形式传入,方法内部会遍历 String 中的每个元素,为其生成对应的 Token,也就是我们最后拿到的那个 ArrayList 中的结果。 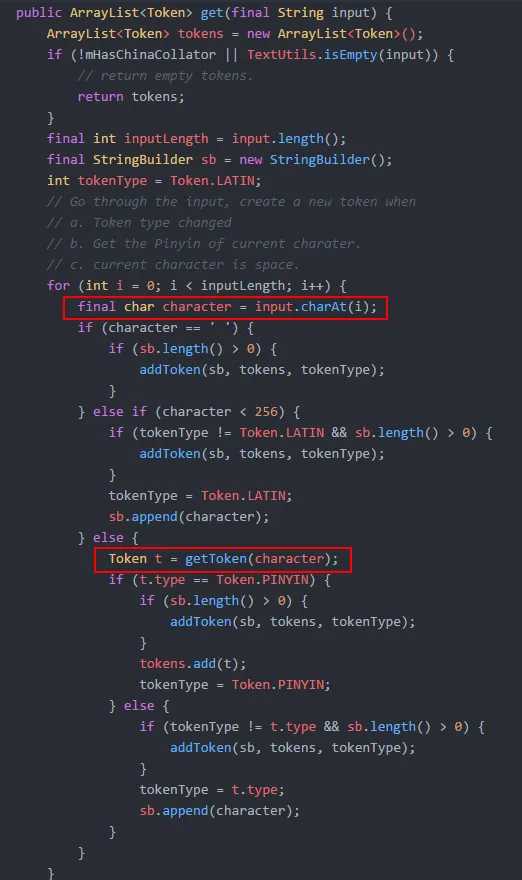 所以最关键的实现是在 getToken 方法中,这里忽略 getToken 前面的 30 来行判断代码,直接看关键部分
所以最关键的实现是在 getToken 方法中,这里忽略 getToken 前面的 30 来行判断代码,直接看关键部分 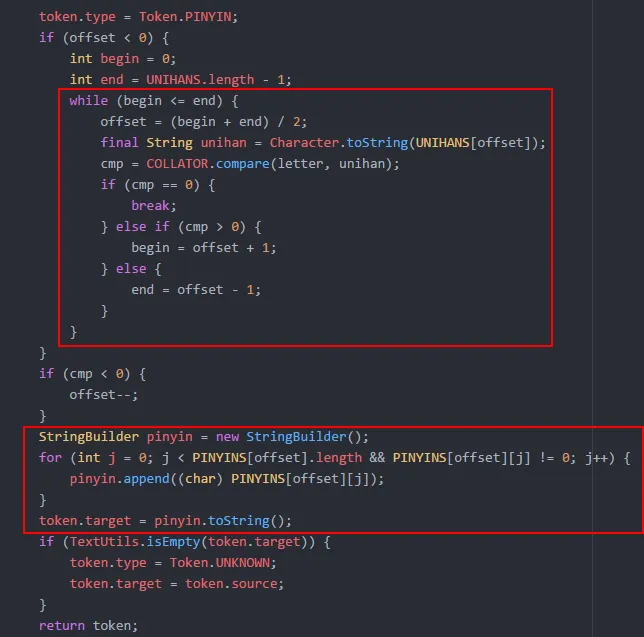 通过二分检索的方式,使用 java.text.Collator 的 compare 方法不断比对 UNIHANS 数组中与输入的汉字同音(注意:这里是同音不是完全相同)的字,最终获取其对应的在 UNIHANS 数组中的下标位置 offset。前面我们提到 UNIHANS 和 PINYINS 是相互对应的,所以这里也能找到 PINYINS 中对应读音的一组 ASCII 码,通过 int 转换成 char,再使用 StringBuilder 进行拼接,就可以获取对应的拼音了,实现思路上还是很简单清晰的。
通过二分检索的方式,使用 java.text.Collator 的 compare 方法不断比对 UNIHANS 数组中与输入的汉字同音(注意:这里是同音不是完全相同)的字,最终获取其对应的在 UNIHANS 数组中的下标位置 offset。前面我们提到 UNIHANS 和 PINYINS 是相互对应的,所以这里也能找到 PINYINS 中对应读音的一组 ASCII 码,通过 int 转换成 char,再使用 StringBuilder 进行拼接,就可以获取对应的拼音了,实现思路上还是很简单清晰的。
性能和不足
在性能上,HanziToPinyin 还是比较客观的,毕竟用了二分检索,在实际测试过程中丢了一篇 5500 多字的文章进行转换,只用了 415ms;
在准确率上,拿了一堆人名和一个国家列表数据进行转换,随机抽取数据都没有发现出错的数据,但是按照这个类的实现上看,如果输入的汉字拼音不与 UNIHANS 中任何一个元素同音,则必然无法得到正确的结果,实际测试中,我随便拿了一些数据测试都没有得到不正确的结果输出,不知道得多生僻的字才能得出个错误结果;
HanziToPinyin 这类并不支持多音字,所以如果一定要考虑多音字的问题,这个类就不适合了;
总结
关于 HanziToPinyin 就介绍到这里,我已经将这个类的代码我已经整理放在 Gist 上(https://gist.github.com/huclengyue/b2286dafb3779e69a71cf57086a8553a),需要的同学自取,如果 HanziToPinyin 不能满足你的需求,那可以考虑使用前面提到的 pinyin4j 和 TinyPinyin。